Ronen here from Gen-X saying that we are currently in Generation Alpha, which is damn close to being called Gen-AI if you ask me and see what’s happening online. Crazy, fascinating, scary, mind provoking, unethical, the next evolution. You name it, and you’ll be right.
let’s dive into the rabbit hole – blue pill or red pill?





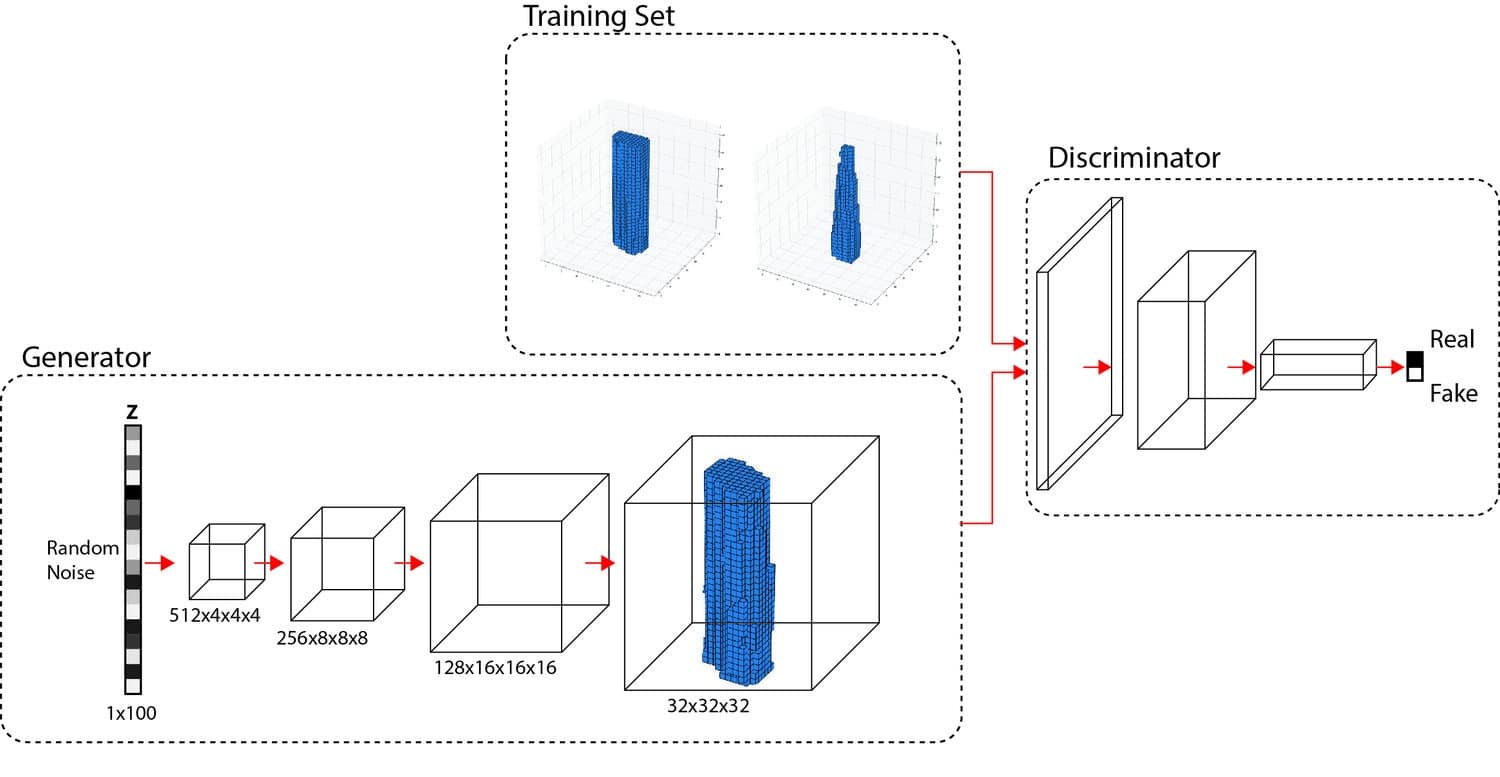
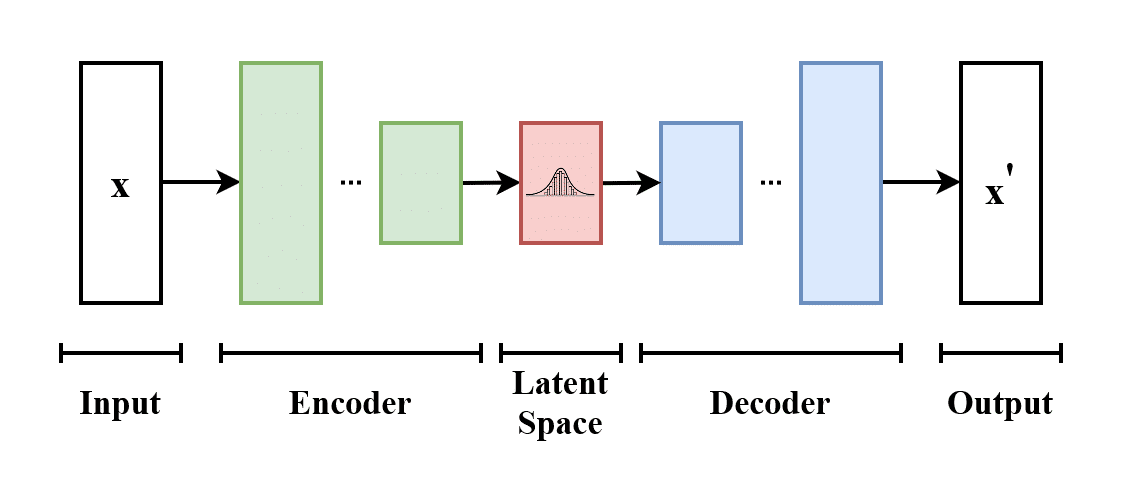
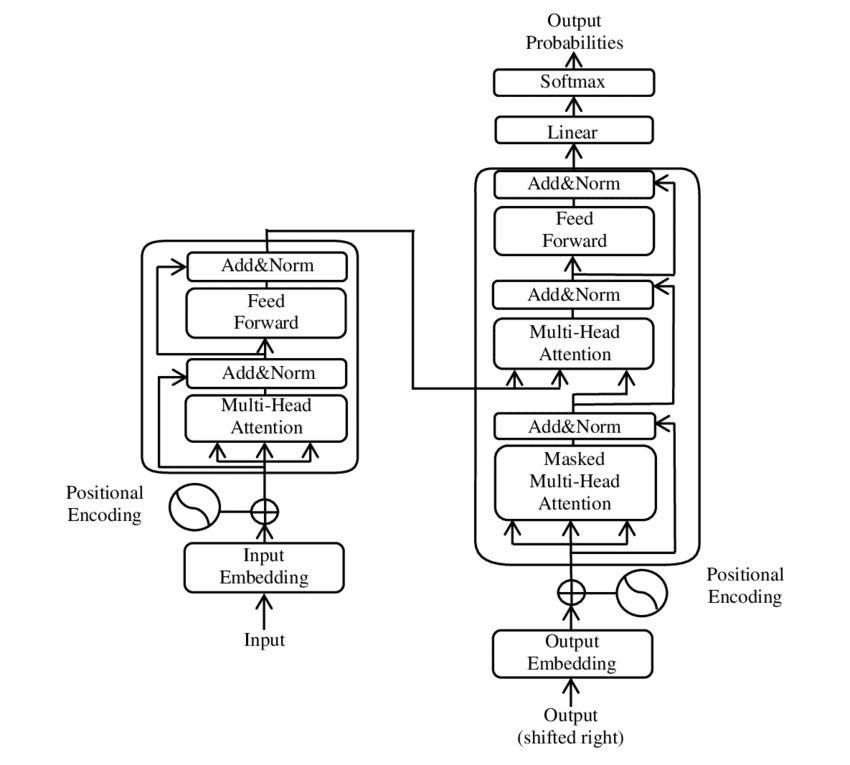



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
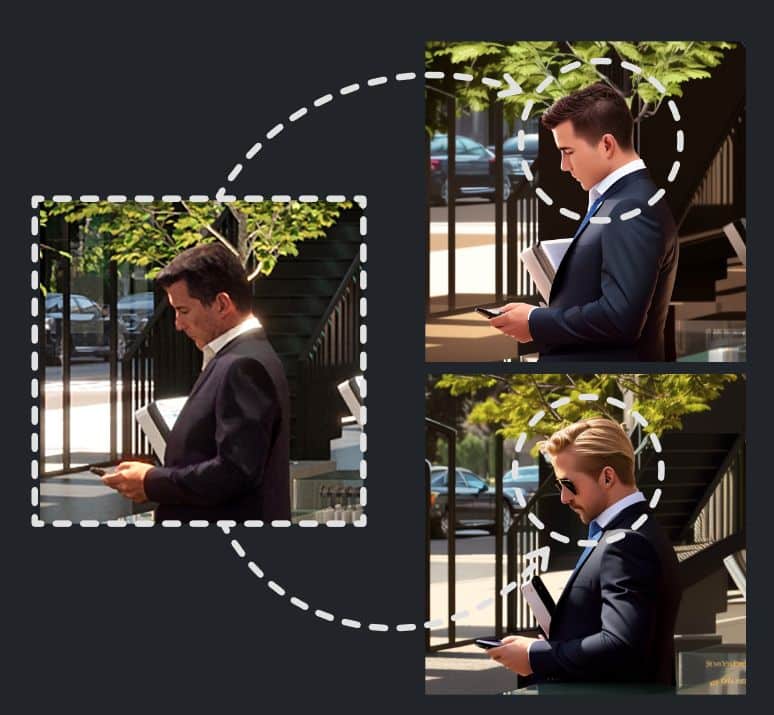{kind=link}



{kind=link}
{kind=link}
{kind=link}

Testing the comments system.
1, 2, 3, check
Continue the discussion at talk.ronenbekerman.com